DTS AutoStage: Delivering a New Vision of a Classic Technology
By Paul Venezia, Chief Architect, DTS AutoStage
The statistics on radio listening across the globe may surprise you. Even in the face of myriad new types of video and audio entertainment platforms, such as on-demand streaming services, radio is a significant and stable part of the audio content diet for the vast majority of the world.
But, even with today’s modern touchscreen interfaces, radio typically lacks the visuals that streaming providers offer to enhance their experience. Most in-car radio systems require the use of a dial set to a particular frequency and display a traditional tuner – until now.
DTS AutoStage™ is up-leveling traditional radio listening by providing metadata linked to broadcasts via a mobile data connection, using cutting-edge API designs and tooling. A global hybrid media solution for the automotive industry, DTS AutoStage introduces metadata into the experience, bringing radio sharply into the foreground with names and logos to complement live station guides, and images of the relevant artist or album cover to accompany the current song or program.

With DTS AutoStage, listeners around the world can see what’s playing on any one of dozens of local broadcast stations instantly, and benefit from a bevy of additional features and functions made possible by the marriage of classic radio broadcasting with modern internet service APIs.
Clouds at 10,000 Feet
The foundation of all DTS AutoStage functions is a microservices-based, event-driven architecture with highly tuned CI/CD workflows. The major players in this architecture are Python with asyncIO, Kubernetes, Helm, PostgreSQL, AMQP (RabbitMQ), Redis and ElasticSearch. While technically provider-agnostic, DTS AutoStage is currently deployed on the Google Cloud Platform. Later, we’ll get into more details on the technology.
Metadata Pipelines – Ingestion
First, let’s take a broad view of how DTS AutoStage works to deliver data and services to automotive clients. The major elements of the solution are metadata ingestion pipelines feeding data to delivery services that respond to API clients. The two major pipelines carry “static” and “dynamic” data.
Static data are provided by radio broadcasters through a variety of methods, including broadcaster-built APIs, data aggregators or through the DTS AutoStage Broadcaster Dashboard, which is a web application that allows broadcasters to add and edit their station data in a well-appointed Vue.js-driven UI. These pipelines bring in data from a large number of sources and distill the information into a single record representing a radio station with fields for general tuning data, such as frequency and band, station logos in several resolutions, station name, slogan, streaming audio URL, social media links and so forth. The data record is then delivered to a client based on the client’s geographic location and measured or calculated broadcast ranges of the radio stations in the area. For instance, a single API request can deliver data for every station that can be tuned in from Central Park West and W. 72nd Street in New York City.
Dynamic data carry real-time information on what song or program is currently on air. Necessarily, the metadata ingestion pipeline must be as fast as possible, aligning with song and program changes as they happen during the broadcast. DTS AutoStage ensures real-time accuracy with an event-driven, real-time pipeline. From the time it receives new metadata for any given radio broadcast anywhere in the world, a push notification is delivered to a client and the display can updated, all within one second.
The dynamic data pipeline must contend with countless ingest types, and data that can be very challenging, as many legacy broadcast software packages are limited in what they can produce. Data-matching is largely based on loosely-defined text strings sent in overloaded fields. For example, some broadcast data will arrive with the artist and title field swapped, or with misspellings or other challenges.
These pipelines are written in Python, with a microservices model that separates the data collection, canonicalization, selection, enrichment and materialization stages into unique, individually-scalable pods that communicate via AMQP messaging. This method produces robust, reliable data management services, while also providing simple methods to distribute data for other services or regions as needed, thanks to the design of AMQP.
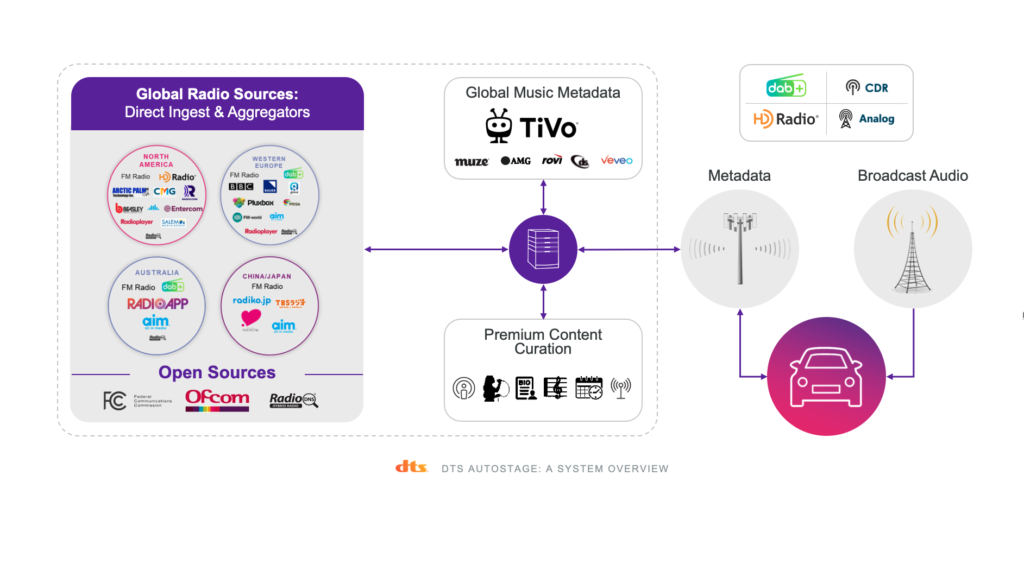
Metadata Pipelines – Delivery
At the other end of the metadata pipelines, delivery services package up the data and respond to API queries from clients. DTS AutoStage leverages a mixture of Python and Golang for front-end delivery tooling, with OpenResty/Nginx sidecars to handle routing, SSL termination, some caching and authentication tasks. This combination is exceedingly stable and flexible, allowing consistent deployment of the same Nginx sidecars in every delivery pod, reducing maintenance and DevOps overhead.
Behind the front-end delivery services are Redis that store and retrieve highly cacheable data, and ElasticSearch to handle less-cacheable and more taxing query types. These are relevant when we need to match IDs and images to song metadata as the information moves through the live pipeline. An example: instead of “Miles Davis” as an artist name and “Kind of Blue” as a title, “Mile Davis – Kinds of Blue” is provided as a single text field. Using fuzzy searches with Levenshtein distances helps here, along with more advanced machine learning functions.
DTS AutoStage also substantially increases performance and scalability by removing the database tier in the delivery critical-path. The heaviest computational work done by delivery endpoints can function without any database queries, relying only on in-memory datasets. These datasets scale spectacularly, providing extremely high performance with fewer moving parts in the delivery mechanism to maximize stability and simplify DevOps. A drawback is increased memory usage, which is offset by product optimization and the low cost of RAM, making the tradeoff well worth it.
Microservices and Event-Driven Architecture
The DTS AutoStage architecture is designed on the microservices and event-driven model, rather than the traditional monolithic models. Every function within the architecture is a container running code designed to perform a single function as fast and as thoroughly as possible.
Through the Google Cloud Platform, we leverage the Google Kubernetes Engine product that provides Kubernetes as an advanced managed service. GKE isn’t a requirement of DTS AutoStage deployment, but it’s highly recommended as Google is at the forefront of Kubernetes technology, and using GKE simplifies the environment substantially. For the most part, managing the Kubernetes clusters involves determining the optimal node specifications, configuring autoscaling and ingress, and managing the global load balancing that directs inbound traffic to the point of presence closest to the client. Delivery services in any GCP region can be deployed easily.
The glue connecting all the components of the DTS AutoStage architecture is AMQP, running on RabbitMQ clusters. RabbitMQ is extremely stable and robust, with a flexible design that makes a variety of otherwise challenging or onerous tasks much simpler. For example, when services are deployed to a new point of presence, redundant federated links are configured between clusters that ride along the GPC internal network and operate in a redundant mesh. Once services begin launching at the new POP, they bind to AMQP routing keys to receive the events they need to perform their task, and the federation automatically routes the events to them as needed.
Additionally, a tap can be placed into the event stream on any given key or set of keys to observe the events flowing through the system, and archive them as needed for analytics, testing or any other reason. If all of the events surrounding image enrichment need to be captured, for example, DTS AutoStage can pull them off the event stream and into a database for analysis. (In fact, DTS developers do this constantly, so we can go back in time and replay events for debugging purposes or other reasons.)
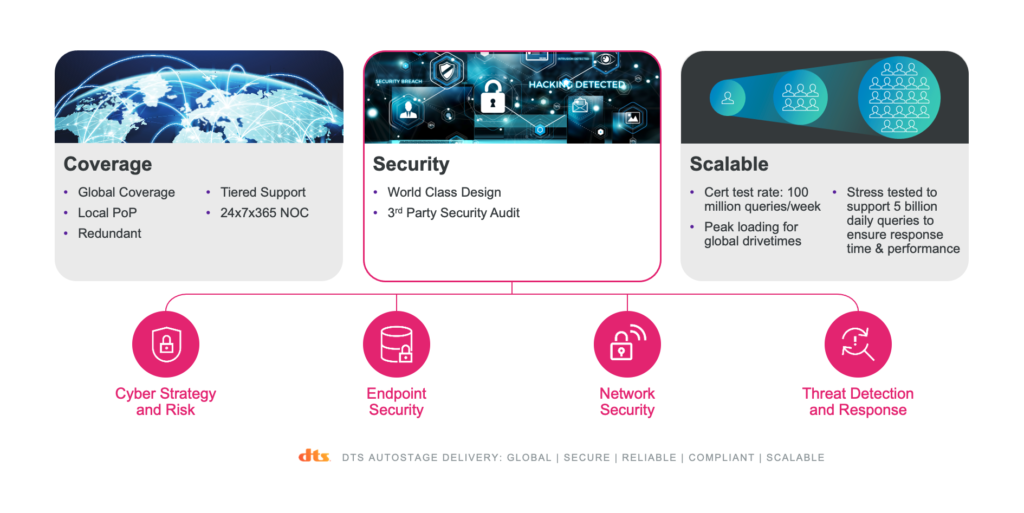
Advanced Security
Security is a major focus within DTS AutoStage, but it can be a challenge to discuss security processes for a specific service as many of those methods should remain unpublished. However, it goes without saying that all traffic to and from the DTS AutoStage API endpoints is SSL/TLS encrypted, and the cloud environment is locked down very tightly. Security measures ensure external IP addresses are not exposed and include strict firewall policies as well as multiple layers of authentication, even for internal systems. Further, AT&T Network Services runs penetration tests against DTS AutoStage production and staging environments, and various development and sandbox tooling.
Front-end authentication mechanisms are multi-faceted and can handle multiple different types of authentication and authorization via the same inbound request, handling services at the edge, at extremely high scale, and scaling horizontally with every delivery pod. Significant portions of the DTS AutoStage authentication stack are written in Lua running within OpenResty for extreme performance, and maintain security mechanisms as far in the front end as possible.
CI/CD, Monitoring and Metrics
To deploy new code to DTS AutoStage environments, the code must first pass through several stages of reviews as well as unit and end-to-end testing before deployment to a staging environment for further examination for scalability or load issues. Frequently, the chaos monkey is introduced to break some things to test resiliency.
Full exercises of each POP, API endpoint and service are run constantly from external testing sites, with escalating alerting. For DTS AutoStage specifically, DTS developed “Periodic Smoke Tests” where test data pass throughout the infrastructure and are tested for validity and latency along the way, at each step through a pipeline, for example, from ingestion to delivery.
The DTS AutoStage staging environment is monitored identically to production, so any potentially problematic code will be detected before it’s deployed to production. Development pipeline processes with Helm facilitate roll-back of changes and environment resets, and allow different versions of various services to be tested together. DTS developers do most of this within their own local environments, as well.
Like every good service, DTS AutoStage relies heavily on logging, metrics collection and widespread monitoring of every part of the infrastructure to detect problems before they happen, such as an event queue not draining fast enough, or inbound data rates dropping slightly where they haven’t before at that time period. DTS AutoStage leverages GCP Cloud Operations (formerly StackDriver) for much of the logging, and DataDog handles metrics collection, dashboards and alerting. These tools provide the ability to easily create multiple different dashboard views and alerting mechanisms, and cross-correlate metrics to narrow down possible issues.

Onward and Upward
Collecting, managing and delivering radio and music metadata on a global scale to automotive clients is a challenging task. DTS AutoStage leverages modern design concepts and proprietary technologies, making the development, enhancement and maintenance of the DTS API more streamlined, flexible and effective at providing an enhanced radio listening experience than anything available on the market today.
DTS AutoStage’s best-in-class design and implementation alleviate break/fix, technical debt and maintenance concerns, allowing more time and energy on next-gen, data-driven features and functionality, such as AI-powered recommendations, integration with popular streaming audio services, the introduction of streaming video to automotive platforms and more. With a visionary roadmap, and stable, scalable infrastructure, DTS AutoStage is shaping a new vision for a classic technology, and building a platform for the future of automotive entertainment and services.
Paul Venezia is designer and chief architect for DTS AutoStage. Paul has over 25 years of experience in information technology and software development with a full-stack skill set encompassing all major aspects of IT from datacenter design and construction to core networking, server infrastructures, storage, virtualization, embedded systems, application, service, and API design and development, with an emphasis on back-end systems and network architecture. More recently, Paul has been focusing on designing and building global API infrastructures leveraging event-driven microservices architectures and cloud platform services.
© 2021 Xperi. All rights reserved. All trademarks are the property of their respective owners.
Latest
Streaming Level Data Powers a New Era of In-Car Radio Insights
Radio data of a different kind Every business has a story to tell and knowing if you’re telling the right story at the right time…
The State of TV Audio: Clear Dialogue Takes Priority
Great sound isn’t just about volume or surround effects—it’s about understanding what’s being said. In a recent consumer survey, 97% of respondents say it’s important…
The Next Frontier of Streaming: Meeting the Demand for Premium Sound
Streaming services have become the primary way for consumers to watch entertainment content. Not surprisingly, as video quality increases, viewers’ expectations for audio quality rise…